Tests de montée en charge : pourquoi c’est critique ?
Contrairement aux tests de performance qui mesurent la vitesse d’exécution, les tests de montée en charge évaluent la capacité de votre application à supporter un nombre croissant d’utilisateurs simultanés sans s’effondrer. C’est la différence entre « Est-ce que mon site est rapide ? » et « Combien d’utilisateurs mon application peut-elle gérer en simultané ? ».
Les enjeux de la montée en charge
Dans notre expérience sur plus de 200 projets, 85% des applications métiers n’ont jamais été testées sous charge réelle avant leur mise en production. Les conséquences :
- Crash applicatif lors des pics de trafic imprévisibles
- Perte de revenus directe pendant les indisponibilités
- Coûts d’infrastructure surdimensionnés par méconnaissance des limites réelles
- Expérience utilisateur catastrophique lors des montées de charge
Quand tester la montée en charge ?
Notre recommandation : validez vos seuils avant chaque évolution critique de votre activité :
- Avant un lancement commercial : campagne marketing, partenariat
- Avant une évolution majeure : nouvelle fonctionnalité, refonte
- Périodiquement : réévaluation annuelle des capacités
Notre méthodologie générale de test
Étape 1 : Définir les profils de charge utilisateur
La clé d’un test de montée en charge réussi : modéliser fidèlement vos utilisateurs réels et leurs comportements distincts.
Questions à se poser :
- Quels sont vos différents types d’utilisateurs ?
- Quelle est la répartition du trafic entre ces profils ?
- Quels sont leurs parcours et actions typiques ?
- À quels moments ont lieu les pics d’activité ?
Méthode de profilage :
- Analyser les logs existants pour identifier les patterns d’usage
- Segmenter par comportement : utilisateurs passifs vs actifs, sessions courtes vs longues
- Quantifier les ratios : pourcentage de chaque profil dans le trafic simultané
- Identifier les pics : horaires et saisonnalité des charges maximales
Étape 2 : Cartographier les endpoints critiques
Nous identifions systématiquement les points de stress de l’application selon deux critères :
Endpoints à forte sollicitation :
- Points d’entrée principaux (login, accueil)
- Fonctionnalités les plus utilisées (recherche, consultation)
- APIs appelées en boucle ou très fréquemment
Endpoints à forte complexité :
- Traitements algorithmiques lourds
- Requêtes base de données complexes
- Intégrations avec des services externes
Cette cartographie permet de concentrer les tests sur les 20% d’endpoints qui supporteront 80% de la charge.
Étape 3 : Calculer les seuils de charge réalistes
Le piège classique consiste à déduire directement des “visiteurs/mois” un nombre d’utilisateurs simultanés. En pratique, il faut raisonner à partir des sessions, de leur durée et de la répartition du trafic dans le temps.
Règle de conversion générale :
- Données: sessions/mois, durée moyenne d’une session, répartition horaire (heures de pointe).
- Concurrence moyenne ≈ arrivées par minute × durée moyenne d’une session.
- Heure de pointe: multipliez cette concurrence par 3 à 8 selon votre secteur et vos campagnes.
- Rafales (notifications, actu chaude): ajoutez x1,5 à x3 si nécessaire.
Coefficients de pic selon le secteur :
- E-commerce : x3 à x5 (soldes, Black Friday)
- Médias : x10 à x20 (actualité chaude)
- Applications métiers : x2 à x3 (heures ouvrées)
- Services publics : x5 à x10 (dates limites)
Les outils et environnements de test de charge
Notre stack technique pour les tests de montée en charge
K6 + Grafana : notre référence pour simuler la montée en charge
- Scripts de charge progressifs et personnalisables
- Métriques en temps réel : utilisateurs simultanés, taux d’erreur, temps de réponse
- Rapports de montée en charge automatisés
Architecture de test :
Générateur de charge K6 → Application testée → Monitoring Grafana
Base de données + Logs systèmeEnvironnements de test multiples
Environnement de préproduction :
- Configuration identique à la production
- Objectif : tester la capacité actuelle sans risque
Environnement de test renforcé :
- Ressources supérieures (CPU/RAM doublés ou plus)
- Objectif : projeter les gains d’un scaling vertical
Cette approche nous permet de projeter précisément les besoins en ressources selon l’évolution attendue de votre trafic.
Analyser les seuils : identifier les points de rupture
Interpréter les paliers de montée en charge
Les tests révèlent généralement 4 zones distinctes :
🟢 Zone de confort : 0% d’erreur, temps de réponse optimal
- Application stable sous cette charge
- Ressources système non saturées
🔵 Limite de capacité nominale : 0% d’erreur maintenu, léger ralentissement
- Seuil recommandé pour le fonctionnement normal
- Ressources à 70-80% d’utilisation
🟡 Zone de dégradation contrôlée : 2-5% d’erreurs sporadiques
- Acceptable ponctuellement lors de pics
- Surveillance renforcée nécessaire
🔴 Point de rupture critique : >10% d’erreurs
- Indisponibilité partielle ou totale
- Intervention technique urgente requise
Identifier la ressource limitante
Le goulot vari selon l’application, la limite peut venir de nombreuses causes :
Saturation CPU :
- Requêtes SQL complexes sous charge simultanée
- Algorithmes métiers gourmands
- Gestion simultanée des sessions utilisateurs
Saturation mémoire :
- Cache applicatif mal dimensionné
- Fuites mémoire sous charge soutenue
- Sessions utilisateurs accumulées
Saturation base de données :
- Connexions simultanées limitées
- Verrous (locks) sur les tables
- I/O disque insuffisant
Stratégies de scaling : anticiper la croissance
Levier 1 : Scaling vertical
Principe : Augmenter la puissance d’un seul serveur (CPU, mémoire) pour absorber plus de trafic.
Avantages :
- Mise en œuvre rapide
- Gains linéaires et prévisibles
- Pas de complexité architecturale
Projections typiques :
- Doublement CPU/RAM → +80-100% d’utilisateurs simultanés
- Quadruplement → +300-400% d’utilisateurs simultanés
Levier 2 : Auto-scaling horizontal
Principe : Ajout automatique d’instances selon la charge d’utilisateurs simultanés.
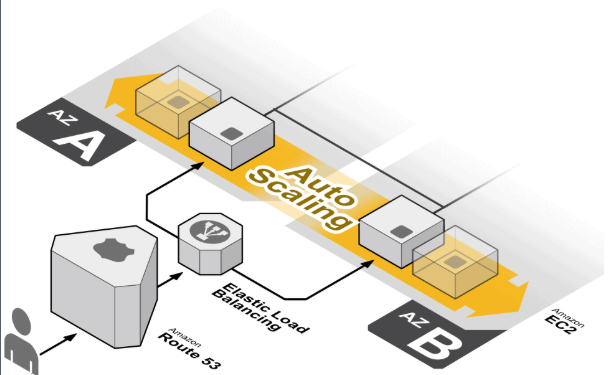
Avantages:
- Elasticité
- Tolérance aux pannes
- Adapté aux pics
Prérequis techniques :
- Load balancer avec health checks
- Sessions externalisées
- Application stateless
Capacité théorique : Quasi-illimitée avec une architecture composable adaptée.
Étude de cas : plateforme de recrutement
Contexte du projet
Secteur : Recrutement digital
Problématique : Anticiper une croissance forte après le lancement d’une nouvelle campagne marketing
Enjeu : Valider que la plateforme supporterait le pic de trafic sans crash
Analyse des profils utilisateurs spécifiques
Candidats (75% du trafic simultané) :
- Sessions courtes mais fréquentes (10-15 minutes)
- Actions simples : consultation d’annonces, candidature
- Pic d’activité : 18h-20h en semaine
Recruteurs (25% du trafic simultané) :
- Sessions longues avec actions complexes (45-60 minutes)
- Recherches multicritères, gestion d’annonces, tri de candidatures
- Activité répartie sur les heures ouvrées
Ratio observé : 3 candidats pour 1 recruteur connectés simultanément
Endpoints critiques identifiés
Forte sollicitation :
/api/login: point d’entrée, charge de connexions simultanées/api/announcements/search: recherche d’annonces par les candidats/api/candidate/{id}: consultation massive de profils
Forte complexité :
/api/announcements/{id}/search-candidates: algorithme de matching/api/recruiter/dashboard: agrégation temps réel des statistiques
Tests de montée en charge réalisés
Configuration initiale :
- Serveur unique 4 vCPU/12GB
- Application Symfony + MariaDB
Résultats des tests progressifs :
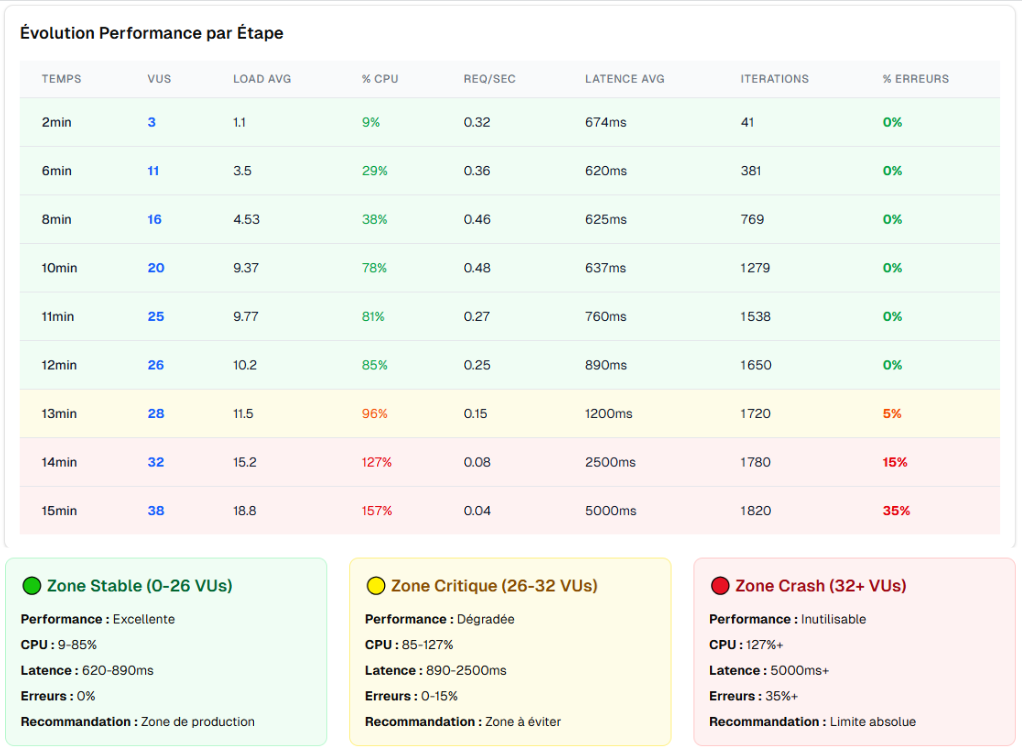
🟢 0-25 utilisateurs simultanés : Zone de confort
- 0% d’erreur, temps de réponse < 500ms
🔵 26-30 utilisateurs simultanés : Limite nominale
- 0% d’erreur maintenu, temps de réponse 500-800ms
- CPU à 70-80%
🟡 31-35 utilisateurs simultanés : Dégradation
- 2-5% d’erreurs sur les recherches complexes
- Temps de réponse > 1s
🔴 36+ utilisateurs simultanés : Rupture
- 15-35% d’erreurs selon la charge
- Timeouts sur l’algorithme de matching
Solutions déployées
Levier 1 – Scaling vertical :
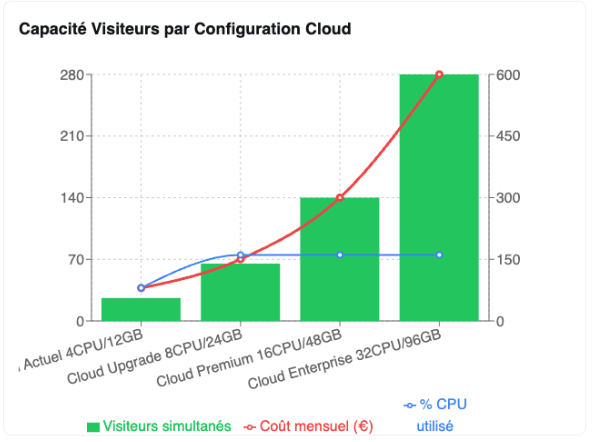
Une simulation sur un 2ème serveur permet d’étalonner une projection de capacité sur une instance avec d’avantage de CPU:
- 4CPU ⭇ 26 Visiteur Simultanés
- 8CPU ⭇ 65 Visiteur Simultanés
- 16CPU ⭇ 140 Visiteur Simultanés
- 32CPU ⭇ 280 Visiteur Simultanés
Gain potentiel : +977% de capacité
Levier 2 – Cache objet :
Après analyse des métriques de production, nous avons introduit un cache objet pour certains éléments des offres et des candidatures les plus consultés. En stockant ces objets en mémoire, on réduit les lectures PostgreSQL et les cycles CPU.
Gain : +20% de capacité
Levier 3 – Scaling horizontal :
Ce levier n’a pas été mis en place, mais cette dernière option permettait d’augmenter la capacité de la charge CPU.
Résultats finaux
Capacité validée : 85 utilisateurs simultanés sans dégradation
Équivalent trafic : ~600 000 visiteurs mensuels
Marge de sécurité : x3 par rapport au trafic initial
Validation terrain :
- Campagne marketing réussie
- Pics jusqu’à 60 utilisateurs simultanés gérés sans incident
- Croissance de 180% du trafic en 4 mois
Recommandations pour vos tests de charge
Démarche progressive recommandée
Étape 1 – Audit initial (1 semaine) :
- Analyser vos profils utilisateurs actuels
- Identifier les endpoints critiques de votre application
- Réaliser les premiers tests de seuils
Étape 2 – Plan de scaling (2-3 semaines) :
- Prioriser les optimisations selon le ROI
- Implémenter les solutions (scaling vertical, optimisations)
- Retester la nouvelle capacité
Étape 3 – Validation terrain (1 mois) :
- Monitoring renforcé des pics réels
- Ajustements basés sur les données de production
- Planification de la prochaine étape de croissance
Métriques essentielles à surveiller
Capacité applicative :
- Nombre d’utilisateurs simultanés supportés
- Taux d’erreur par palier de charge
- Temps de réponse sous charge croissante
Ressources système :
- CPU moyen/pic par palier d’utilisateurs
- Mémoire consommée selon la charge
- Connexions base de données simultanées
Seuils d’alerte recommandés :
- 80% de la capacité validée = alerte préventive
- 90% de la capacité validée = alerte critique
- Taux d’erreur >2% = investigation immédiate
FAQ : Questions fréquentes sur les tests de montée en charge
Quelle différence entre test de performance et test de montée en charge ?
Les tests de performance mesurent la vitesse d’exécution (temps de réponse, latence) tandis que les tests de montée en charge évaluent la capacité à supporter un nombre croissant d’utilisateurs simultanés. Un site peut être rapide avec 5 utilisateurs mais s’effondrer avec 50 utilisateurs simultanés.
À quelle fréquence faut-il réaliser des tests de montée en charge ?
Nous recommandons :
- Avant chaque évolution majeure de l’application
- Avant les campagnes marketing importantes
- Annuellement pour réévaluer les capacités
- Après optimisations pour valider les gains
Comment estimer le nombre d’utilisateurs simultanés à tester ?
Utilisez cette règle approximative : 50 000 visiteurs mensuels ≈ 15-20 utilisateurs simultanés. Appliquez ensuite un coefficient de pic selon votre secteur (x2 à x5 pour la plupart des applications métiers).
Quel budget prévoir pour des tests de montée en charge ?
Le budget varie selon la complexité :
- Audit simple : 3-5 jours (2 500-4 000€)
- Tests complets avec optimisations : 10-15 jours (8 000-15 000€)
- Mise en place auto-scaling : 15-25 jours (12 000-25 000€)
Peut-on tester la montée en charge en production ?
Non, c’est fortement déconseillé. Les tests de charge peuvent provoquer des ralentissements ou crashes. Utilisez toujours un environnement de préproduction identique à la production.
Quels outils recommandez-vous pour les tests de montée en charge ?
Notre stack préférée : K6 + Grafana pour la génération de charge et le monitoring. Pour les applications plus simples, Apache JMeter reste une alternative viable et gratuite.
Comment interpréter un taux d’erreur de 5% lors des tests ?
Un taux d’erreur de 5% indique une dégradation contrôlée. C’est acceptable ponctuellement lors de pics, mais pas pour un fonctionnement normal. Visez 0-2% maximum pour votre capacité nominale.
Faut-il tester tous les endpoints de l’application ?
Non, concentrez-vous sur les 20% d’endpoints critiques qui génèrent 80% de la charge : points d’entrée, fonctionnalités les plus utilisées, et traitements les plus complexes.
Conclusion : Anticiper la croissance par les tests de charge
Les tests de montée en charge ne sont pas qu’une validation technique : ils constituent la clé pour anticiper sereinement la croissance de votre activité. Notre expérience confirme que les applications testées sous charge évitent 90% des incidents liés aux pics de trafic et permettent de planifier les investissements infrastructure avec précision.
Nos recommandations clés
- Testez avant de grandir : validez vos seuils avant chaque étape de croissance
- Modélisez vos vrais utilisateurs : charge simultanée réaliste selon vos profils
- Identifiez vos goulots : CPU, base de données ou architecture applicative
- Scalez par étapes : vertical d’abord, horizontal pour les gros volumes
- Monitorer en continu : anticipez les besoins avant les ruptures
Prêt à valider votre capacité de montée en charge ?
Chez Sooyoos, nous accompagnons les entreprises dans la validation complète de leur capacité de montée en charge. De l’audit initial aux solutions de scaling, notre équipe d’experts vous guide pour transformer l’incertitude technique en croissance maîtrisée.
Besoin d’un test de montée en charge ?